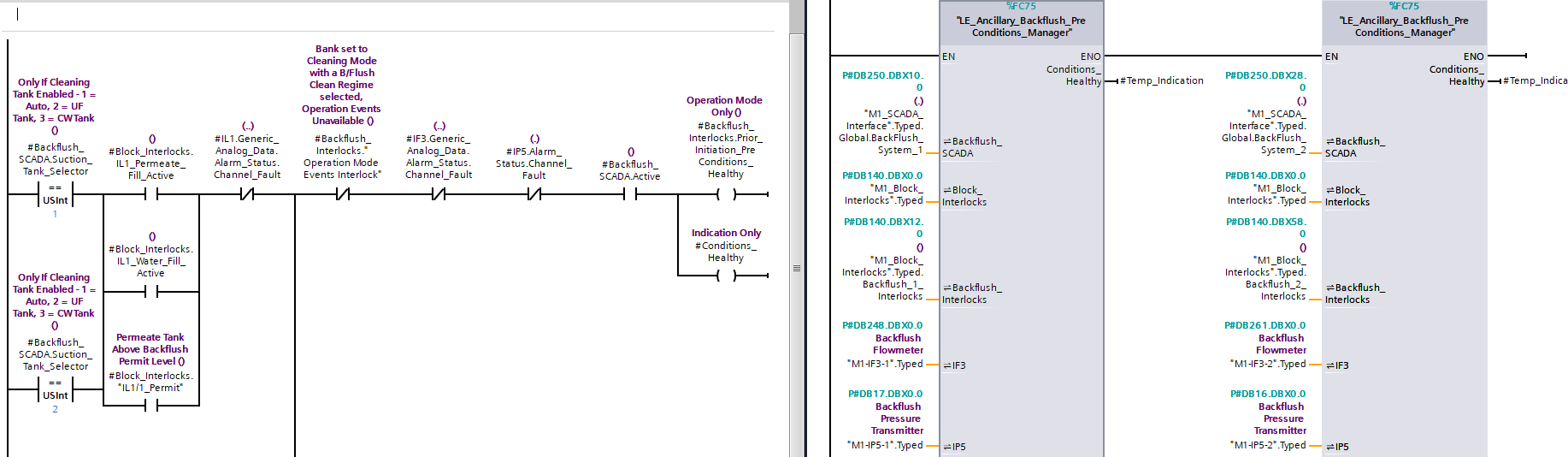

In day to day automation work, it is common to write logic for one system, verify that it behaves correctly, then duplicate it for another system that performs the same overall function. For example, you might complete all the logic for System 1, copy it into System 2, then adjust parameters, tag names, and instance data. This manual process often feels repetitive, but it is incredibly useful because it exposes subtle differences between the systems and helps you validate their behaviour before committing to a shared design.
During this early phase, you typically discover how each system is wired, what field data it relies on, and whether the structures behind the two systems are genuinely aligned. Once both systems operate correctly and consistently, you have enough confidence to start refactoring and turning duplicated logic into a single maintainable block.
Why Start With Copy and Paste
At first glance, copy and paste feels like the wrong solution. However, duplicating the logic gives you a controlled way to test two systems independently. This separation is valuable because it reveals questions such as:
- Do both systems follow the same sequence of operations, or are there exceptions?
- Are the required inputs identical, or does one system include extra instrumentation?
- Are the alarm or fault conditions the same for each system?
- Do the data structures differ, even slightly, between the two implementations?
Working through these differences while the logic is still duplicated lets you make corrections without affecting the other system. Once both systems behave identically, and you are confident that any differences have been resolved or deliberately accounted for, you can safely move toward abstraction.
Spotting Common Logic and Shared Structures
The next stage is identifying what is shared and what is unique. In many industrial systems, the behaviour is largely the same but the tags differ. For example, both System 1 and System 2 might monitor a process flow using a flow meter. The only distinction might be tag naming, such as:
System1.FlowMeterSystem2.FlowMeter
If the logic uses the flow meter in the same way, then instead of hardcoding system specific tags, you can replace them with a single generic input on a function or function block interface. The same applies to state bits, process interlocks, permissives, or control parameters. By gradually identifying these common elements, you build a clear picture of what can be abstracted into a shared block.
Creating the Abstract Function or Function Block
When you reach the point where both systems share the same underlying behaviour, you can create a dedicated function or function block. The block becomes the home for all logic that both systems rely on. Its job is to implement the behaviour once, while receiving system specific data through its interface.
Typical steps include:
- Create a new block (usually a function block if system state must persist).
- Define descriptive interface parameters, such as
FlowMeter,Level,Enable, orCommand. - Move the logic from both systems into the block, remove system specific tags, and replace them with interface variables.
- Call the block once for each system, mapping the appropriate tags to each call instance.
This structure keeps each system’s data separate while centralising the logic. The result is cleaner, easier to read, and significantly easier to maintain.
Understanding When Refactoring Is Not Suitable
Not every system is suited to shared logic. While refactoring often works well, sometimes the earlier duplication reveals a genuine difference.
For example, System 2 might include an additional level sensor, or it may require a unique interlock that System 1 does not have. If you force both systems into a single shared function block when their requirements differ, you risk building a block that is too generic or that behaves incorrectly under certain conditions.
If you discover a structural difference between systems that is fundamental, it is appropriate to keep the logic separate. This protects system integrity and prevents accidental coupling of behaviour that should not be shared.
Benefits After Refactoring
Once your logic has been refactored into a single reusable block, the long term advantages become obvious. Maintenance is easier because you only update the logic in one place. Consistency improves because every system uses the same tested code path. Training and onboarding become simpler because engineers only need to understand one block instead of several near duplicates.
For example, if you later decide that every system now requires a level input, you simply add a Level parameter to the block interface. Each system then receives its own level value, and the shared logic handles it consistently. You can test the change using a single system and gain confidence that all systems will behave the same way, assuming their instance data is wired correctly.
Ensuring Long Term Maintainability
Maintaining control logic is far easier when the structure is intentional rather than accidental. Refactoring provides a controlled way to reach that structure. By verifying behaviour first, then abstracting, you avoid the common trap of prematurely building a generalised block that does not fit all use cases. Instead, you end up with a block that you know is valid, consistent, and suited to both current and future requirements.
This workflow supports good engineering practice, reduces errors, and ensures that changes later in the project lifecycle do not involve repetitive edits across multiple networks or programs. Ultimately, it helps keep your automation environment clean, predictable, and scalable as the project grows.
Consider Future Divergence Between Systems
Once two or more systems share the same function block, they are tied to the same underlying behaviour. This is powerful for maintenance, but it also means the systems are no longer free to evolve independently. If, later in the project lifecycle, one system requires new instrumentation or a change in behaviour that the others do not need, you may reach a point where the shared block no longer fits all use cases.
In these situations it is perfectly acceptable, and sometimes necessary, to reverse the refactor. Splitting the logic back into system specific implementations ensures that each system can behave according to its own requirements without forcing the others to adopt changes they do not need. Keeping this in mind helps avoid forcing a shared design onto systems that may diverge over time.