
Since TIA Portal came along, there’s been an argument between whether or not you should allow TIA Portal to “Optimize” your data.
Set to ON by default, this allows the compiler to reshuffle your data to minimize wastage and supposedly speed up access
Personally, I never use optimized data if I can get away with it. I prefer to know where exactly my instance and global data is kept
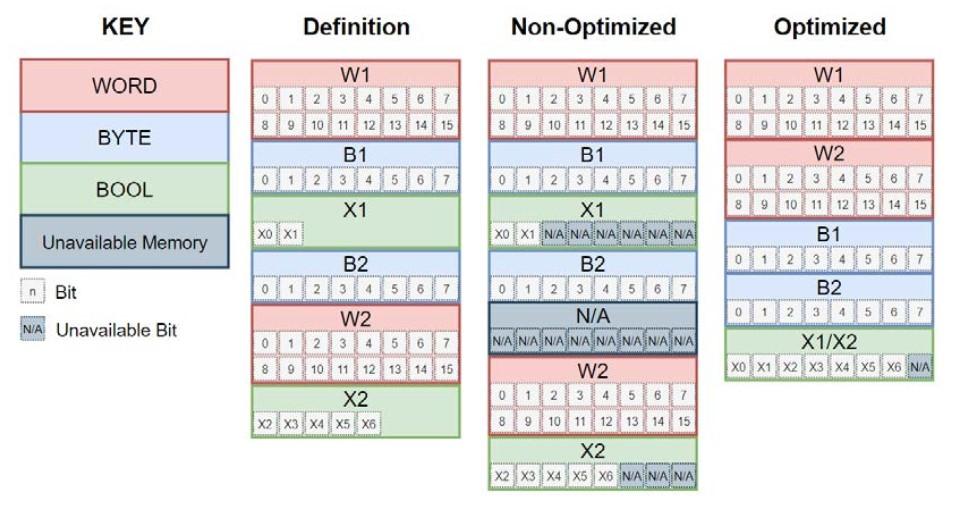
Optimized Data
Highlights
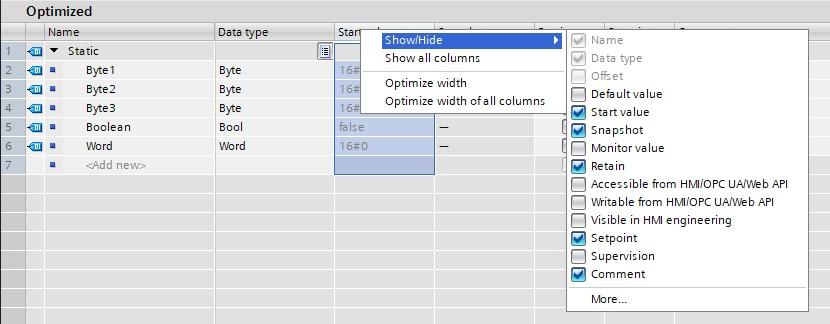
- No Offset address available (As shown to the right)
- Order of variables is not actually adhered to once compiled
- Wastage of memory is reduced
- Expansion of data into “Reserved” memory
Siemens have enabled Optimized data by default, and for the most part, you won’t even realise the difference.
For people who just want to get on with programming a small system, or creating a safety interlock program, optimized data is just fine.
Memory Management
One of the key benefits of optimized data is the reduction of wasted memory. This becomes really apparent if you start spotting Boolean variables between lots of different data types. Optimized blocks will re-organize that data so that there are no wasted bytes between booleans. Non-Optimized blocks would be full of wasted space here. (Refer back to the image at the top of this post)
Does any of this actually affect your programming? No, not really. You don’t even notice it really. Since TIA Portal is symbolic, the variables used to symbolize memory locations are all that matters. None of this changes if we’re optimizing the data.
Reserving Memory
Another great benefit of optimized data is the ability to reserve memory for expansion:

Having data reserved has two major effects on the PLC
- You won’t cause a reinitialization of the data by expanding into reserved memory
- The block is larger than the data contained within it (Variables + remaining memory reserve)
An example of the size of this block is here (3 Bytes, 1 Bool and 1 word = 380 bytes)

This can’t be done with Non-Optimized data, with Non-Optimized data, you will cause a reinitialization if you modify the data once its in the PLC.
For contrast, look at the “Optimized” block with optimization turned off…

Much smaller, because there’s no reserved memory. It’s also 6 bytes smaller due to no header requirements by the Optimization system.
Small blocks may not pay to have optimization enabled on, but there’s a reason why Siemens want you to leave Optimization on, and issues that it can cause if you turn it off… We’ll cover that later!
Non-Optimized Data

Highlights
- Offset from first data point
- Memory is allocated at compile time
- Unable to reserve memory for growth
- Poor design can waste memory
Reinitialization Of Data
Unlike Optimized data (that has a memory reserve allocated), Non-Optimized data wants to reinitialize for any change, even comments.

The reason for this is that the block is allocated memory depending on the size of the Offset at the end of the compile process. This memory is defined and allocated in the PLC as part of the download process.
The above picture shows that “Due to changes in the DB, all data values, including retentive data, will be initialized with their defined start values“… This basically means your going to lose everything in affected Data Blocks.
You can’t stop this from happening with Non-Optimized data blocks. But you can use Snapshots and Start Values to try and reduce the impact.
Limitations
Optimized data falls down when you want to use memory management instructions such as FILL or BLKMOV
This is because both of those instructions require access to the starting offset and structure of the data. Because Optimized data doesn’t have offsets or a rigid layout to the structure, those instructions cannot be used.
There are other methods that can be used though, and in most cases there’s nearly always an alternative method to do what you need to do. However, TIA Portal will throw an error saying “You cannot access this data from an optimized location”, which leads you into turning off Optimized data for that block… This causes an unseen issue…
Mixing Optimized and Non-Optmized Data
It may not seem like it, but mixing the two data types causes serious memory wastage. This is because Optimized data cannot be passed to Non-Optimized blocks without the data being re-constructed into offset-data.
This means we’re creating copies of Optimized data to work with in Non-Optimized spaces… When you start nesting blocks and calling multiple instances like this, suddenly you are creating vast amounts of copies and the PLC runs out of memory.
You’ll start seeing issues that talk about the interface of a Function Block being too large too, because the instance data is bearing the brunt of the conversion process.
Why Non-Optimized?
Personally, I find that the non-optimized approach is cleaner, simpler to understand and in most cases, the scan-time is quicker with non-optimized. However, the amount of data that the blocks take up in the PLC is noticeably higher

Good explanation…!
Thank you 🙂