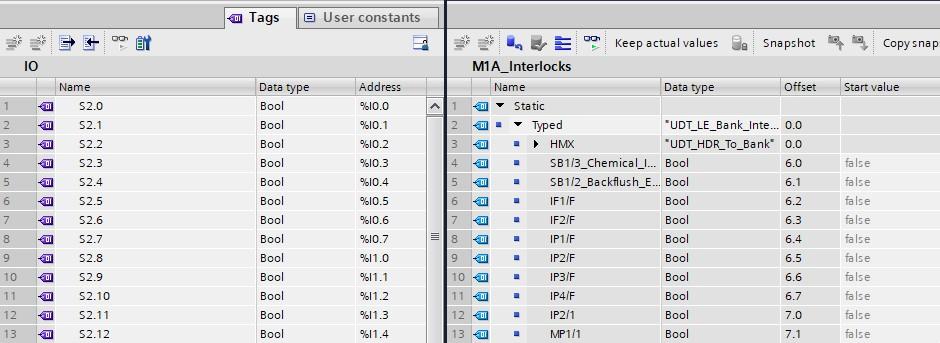
Apart from the obvious that one is a purple icon and the other is a blue, the difference between how these two objects should be used is very misunderstood.
I came from an Allen Bradley background, before using Siemens, and I can tell you that it’s even MORE misunderstood in Allen Bradley with their “Local” and “Global” tags.
The key difference between a Tag and a Variable is their Scope.
What Is Scope?
Scope is a word given to how the data is accessed, or rather, where the data is accessed. We actually see this all the time in Function Blocks:
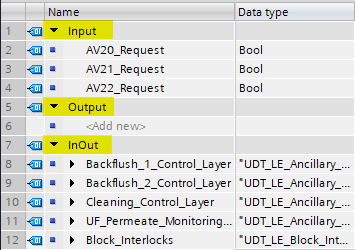
Depending on where you put your variable, the Scope defines how that variable is accessed. For example, the AV20_Request variable above is an Input scope, which defines how the data is used. Because it’s an input variable, the data is copied from the connected variable to the instance data.
The InOut variables though, such as Block_Interlocks are not copied, because their scope is InOut. This means the data is referenced instead, changing the behaviour of how that variable is accessed.
Let’s have a look at how this works with Tags:

A Tag is a symbolic reference to a pre-allocated section of memory. The memory allocation can be scoped to either Input, Output or Memory (sometimes called Internal, Memory Flag or simply M-Register)
We can see above that S2.0 through to S2.2 are Input tags, denoted by the %I. Below are some examples and other scope notations.
- %I – Input
- %Q – Output
- %M – Memory
The notation is modified further depending on the data type:
- Input
- Numerical – %I200
- Boolean – %I200.5
- Output
- Numerical – %Q200
- Boolean – %Q200.5
- Memory
- Numerical
- Byte / USint / Sint – %MB200
- Word / Uint / Int – %MW200
- DWord / UDint / Dint – %MD200
- LWord / ULint / Lint – %M200.0 <– Why? I have no idea
- Numerical
Notice how these are similar to the Function Block Interface? Inputs, Outputs and also Static (%M scoped Tags).
Function Block instance data are Variables and their scope is defined by a standardized interface of Input, Output, InOut and Static. None of this funny %M business, just an offset from the first variable. The actual location of the memory in the PLC is handled internally. We don’t know where exactly the memory is
Note: If you are using Optimized Access, you don’t even know the offset. TIA Portal is completely in control of the data.
Access & Memory
The fundamental difference here though is that all Tags are globally accessible. This means they can be accessed from anywhere in the project. It’s all access, no control. They can also Overlap in memory address.
TIA Portal will throw a warning on start addresses that match, but there is nothing stopping you from creating the following:

A ULint or Lint are both 64 bits long (or 8 bytes), if one is starting at M200 and the other at M201, then 7 of the bytes overlap and will cause conflicts when reading / writing.
No warning, just mess when you try and use the tags in a program. This particular issue caught me out many years ago in a Mitsubishi PLC and caused a lot of damage!
Variables can’t overlap memory, not easily anyway. You have to specifically go out of your way to overlap memory in variable space.
Variables can always be accessed globally too, but there’s a few hoops to jump through.
If a variable exists in a Data block, it can be accessed by simply using the Data blocks name and then the variable: DBname.Variable
But if the variable exists in an Instance Data block, then things become relative to where the variable is called in the interface. For example, to access the value Result, that is in Function Block C, which is called by Function Block B, which is called by Function Block A, with FB A having an Instance Data block which contains all other instances, the path would be:
“FB A”.”FB B”.”FB C”.Result
However, if FB B had its own Instance Data block which FB A called in as an InOut interface, the data could be access at
“FB B”.”FB C”.Result
So it’s all relative to where the information is stored with variables, where as Tags are always globally accessed with “TagName“
Offsets
Unlike Tags, Variables rely on offsets from the first variable length
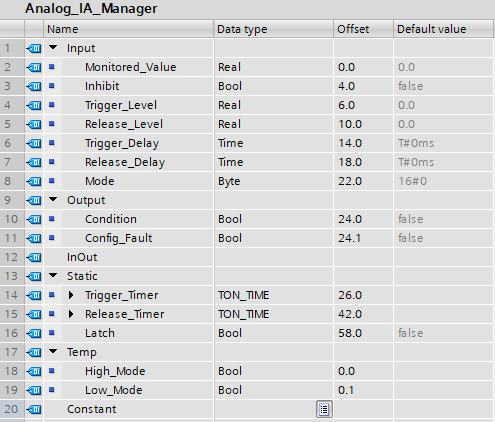
The above interface shows that the first variable “Monitored_Value” starts at offset 0.0
This means that wherever the memory is allocated for this instance, the first variable’s data is at offset 0.0 from that memory allocation – makes sense, it’s the first variable.
From here on in, the offset is dependent upon the data type of the variable before it (and the scope)
The next variable is the Inhibit, which starts at offset 4.0
This is because the Monitored_Value is a Real data type, which is 4 bytes. The first byte was 0, so the last byte is 3, leaving the next byte that is free as 4
However, the next variable Trigger_Level starts at 6?
This is because of 2 rules:
- Bools are 1 Byte long, unless immediately followed by another Bool (up to 8 in total)
- You cannot start a new data type on an odd byte number, unless a Byte follows Bools…
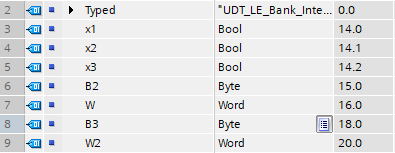
Notice that W2 skips a byte address (17.0), even though it’s free? This is to ensure rule 2 is followed.
The offset approach allows TIA Portal to designate blocks of memory at compile time, which is different to Tags. With Tags, we know where the memory will be BEFORE compile time, with variables we must compile to work out where the data will be.
Destructive Memory
Tags, because they are allocated before compile time, are non-destructive. You can modify the name of a Tag and the memory address of a Tag and still download to a PLC without causing memory-related issues.
Variables are not the same. Because they need to be compiled and the block of memory allocated at compile time, if anything changes, the memory may need to be re-configured to allow for more / less.
This is especially true with Function Block instance data, as if we’re using 20 instances of an FB and add 1 byte to the interface, that’s 20 bytes needed, but they all exist in different locations. The PLC needs to reshuffle a lot of memory, much more than 20 bytes to create enough room to accommodate the new length.
This is why, when modifying variables in Data blocks or Function Blocks, the PLC wants to “Reinitialize” and set variable values back to their default / start values.
When using Tags, this doesn’t happen because there’s only 1 instance of the tag and its tied to memory that is already allocated in the PLC for tag data anyway.
Conclusion
Personally, I move Tag data to Variable data because I prefer to pass all my data through interfaces. I feel that the use of %M addresses is almost pointless as you could create a DB and store your data in more robust format.
The risk with Tags is that it promotes the thinking of “I’ll just access this anywhere” and “But everything cross references nicely”. All of this is fine until you want to re-use function blocks. Now you can’t because Flowmeter 1 and Flowmeter 2 use the same function block and both want to write to %MW200… that doesn’t work.
TIA Portal almost forces you to use variables and data blocks, so apart from using Tags as an abstraction layer, with %I addresses gathering input data and %Q addresses processing output data. I don’t see the need for Tags at all
This is a pretty messy post, but if you have any questions. Hit me up on LinkedIn!